
In yesterday’s post forecasting smartphone penetration I neglected to mention the exact subset of the US population being sampled. The analysis is based on comScore’s sampling which covers only those devices which are the “primary phone” for users over 13 years old and not provided by an employer.
In other words, the population being sampled is not meant to identify how many phones will be in use but rather what is the primary phone for those non-children who choose their own phones.
So the measurement that can be obtained from the S curve analysis is a subset of all phone users and will not identify exactly how many phones will be in use. Given that, this is what that subset looks like:
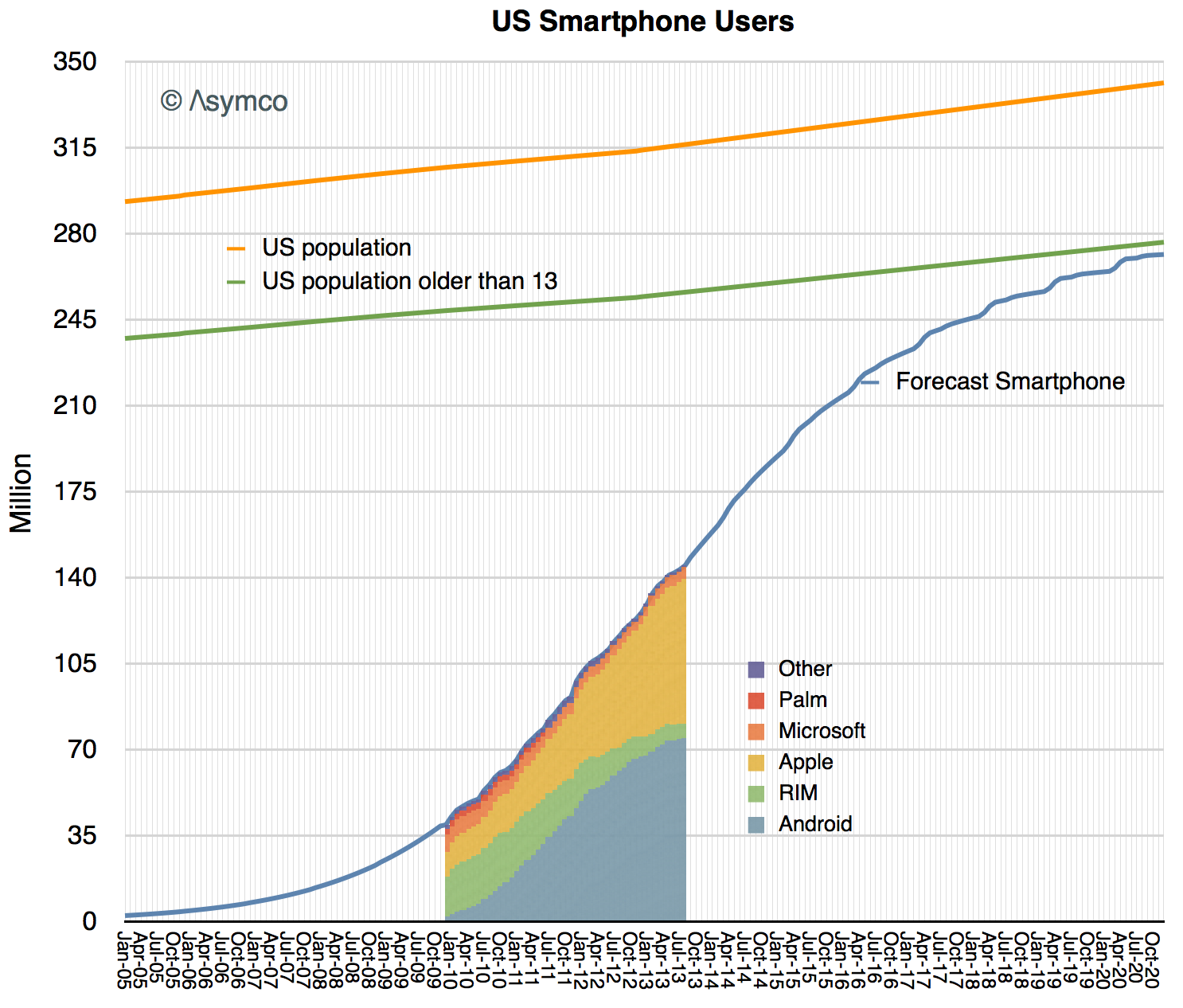
I drew a line showing the census data (and projection) for the US population and estimated what percent of that population might be Continue reading “How many smartphone users will there be in the US?”